Содержание
В главном меню программы «Файл» есть такие пункты меню:
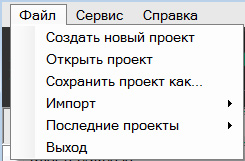
Где можно создать новый проект, открыть проект из интерфейса программы, сохранить проект как, импортировать данные и для удобства поиска ранее открываемых проектов пункт меню «Последние проекты». В открытом проекте работает функция автосохранения, поэтому можно не беспокоиться об утере данных при случайном закрытии программы.
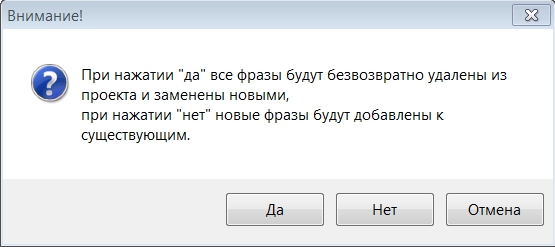
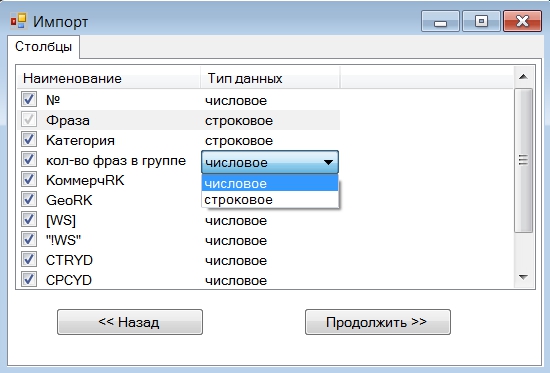
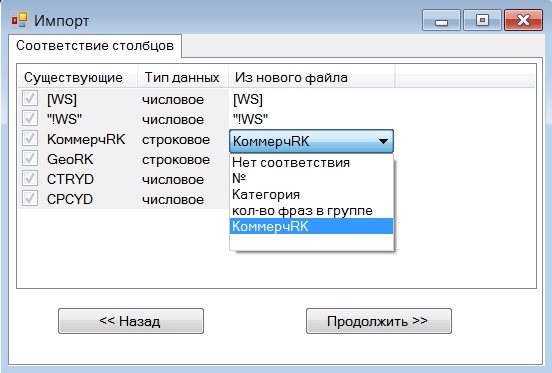
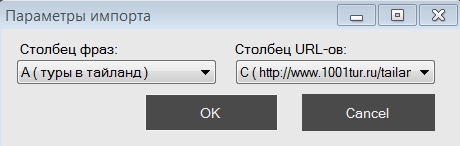
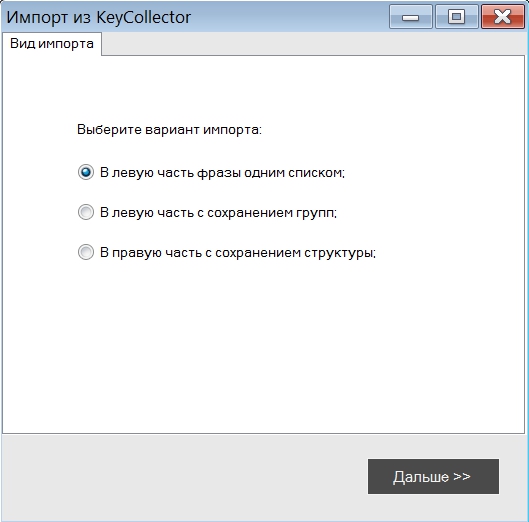
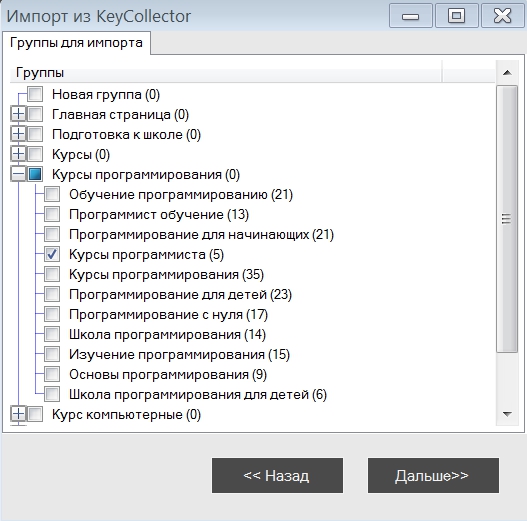
Для начала работы с программой нам надо создать новый проект и собрать или импортировать фразы, с которыми вы планируете работать. В KeyAssort реализовано 5 видов импорта фраз, объединение проектов и импорт структуры семантического ядра:
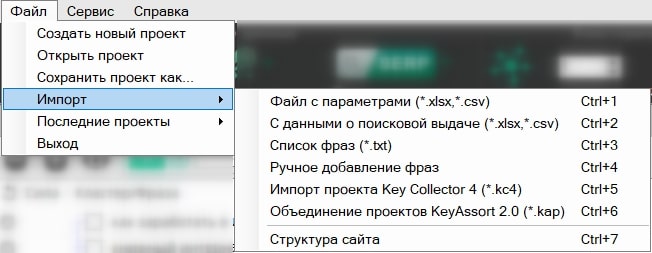

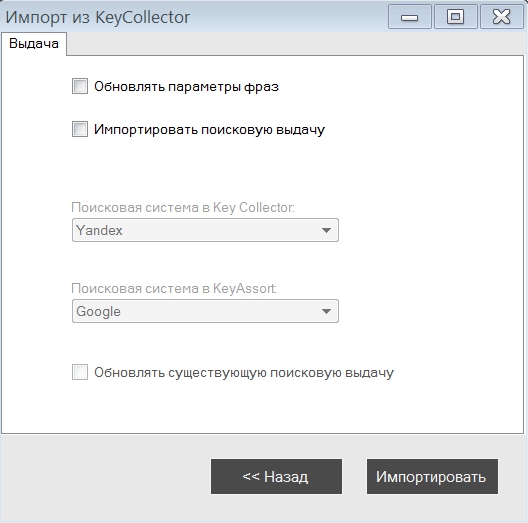
В настройках программы есть 5 пунктов: общие настройки, кластеризация, сбор данных, антикапча и proxy.
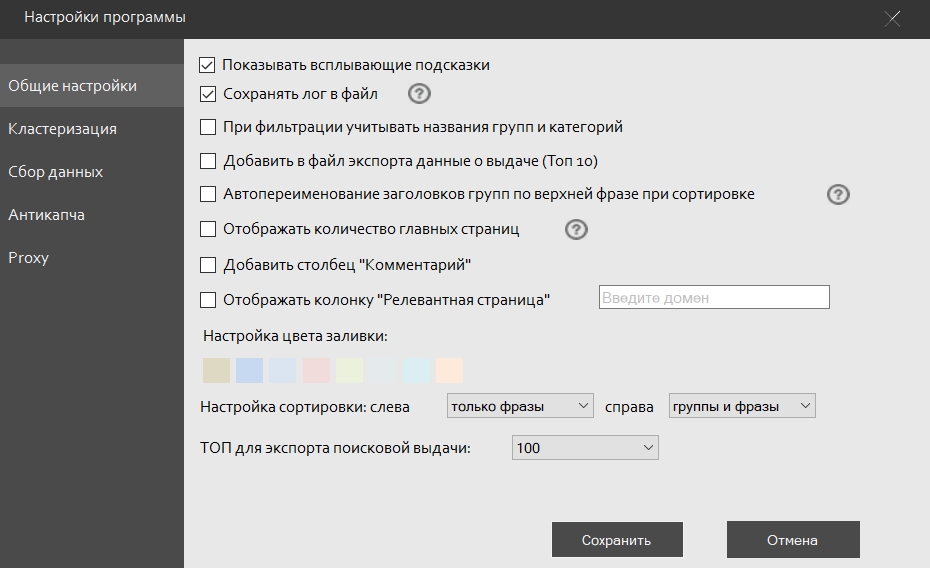
Показывать всплывающие подсказки – При включенной функции при наведении на некоторые элементы интерфейса во всплывающем окне отображаются подсказки по назначению данного элемента.
Сохранять лог в файл – В той же папке, где находится файл проекта, создаётся дополнительный файл, где ведётся лог о работе программы.
При фильтрации учитывать названия групп и категорий – При выключенной функции фильтр будет осуществлять поиск только по фразам, при включенной – по фразам и названиям групп и категорий.
Добавить в файл экспорта данные о выдаче – В файле экспорта напротив каждой фразы отображаются URL, которые были собраны из поисковой выдачи для данной фразы. Напротив названия группы отображается 10 эталонных URL (самых значимых) для данной группы.
Автопереименование заголовков групп по верхней фразе при сортировке - Переименовывает названия групп при сортировках по различным столбцам в левой части программы.
Отображать количество главных страниц - Выводится дополнительный столбец, отображающий количество главных страниц в топе по каждой фразе.
Добавить столбец "Комментарий" - Появляется новый столбец, который позволяет напротив групп и фраз писать произвольный комментарий. Для редактирования нужной ячейки сделайте двойной клик левой кнопкой мыши.
Отображать колонку "Релевантная страница" - Появляется новый столбец, который покажет страницы указанного сайта, ранжирующиеся по соответствующему запросу.
Настройка цвета заливки – Здесь выведены 8 цветов, которыми в интерфейсе программы можно закрашивать строки с фразами и группами. Эти цвета настраиваемые с помощью палитры цветов. Для её вывода нужно кликнуть по цвету, который необходимо заменить.
Настройка сортировки – Функция работает в левой и правой частях программы. Определяет, по каким критериям сортировать готовую структуру: только фразы, только группы, фразы и группы.
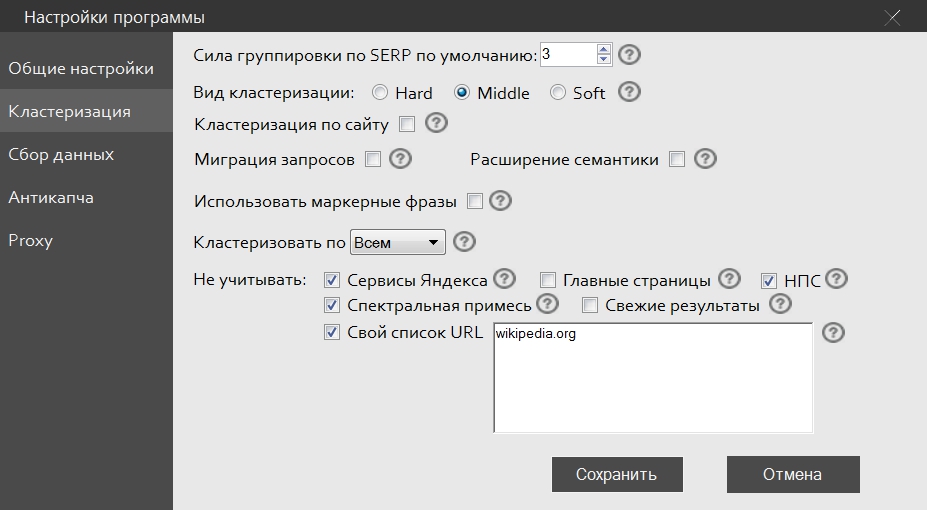
Сила группировки по SERP по умолчанию - Параметр силы группировки отвечает за то, как сильно должны быть похожи запросы, чтобы попасть в одну группу. Чем выше этот параметр – тем точнее получаемые группы, но при этом они уменьшаются в размерах. Технически, сила группировки - это минимальное количество общих URL для образования группы. Экспериментальным путем было определено, что минимальная сила группировки "начисто" для «hard»-кластеризации – 2, для «middle» – 3 и для «soft» – 4. Эти значения подойдут для большинства тематик. Значение силы группировки можно в любой момент откорректировать из интерфейса программы:
Вид кластеризации – Выбор методики группировки фраз. При Soft кластеризации запросы сравниваются на предмет общих URL у всех запросов в группе. Например, у запроса А есть общий набор URL с запросом Б, у запроса Б есть общий набор URL с запросом В. При этом запросы А и В будут объединены в одну группу, не смотря на то, что они могут не иметь общего набора URL. При middle методе мы берем один центральный запрос и сравниваем с ним другие на предмет совпадения урлов. Если количество совпадений больше или равно силе кластеризации, запрос добавляется в группу. При hard кластеризации запросы объединяются только если есть общий для всех запросов набор урлов, тоже больший или равен силе кластеризации.
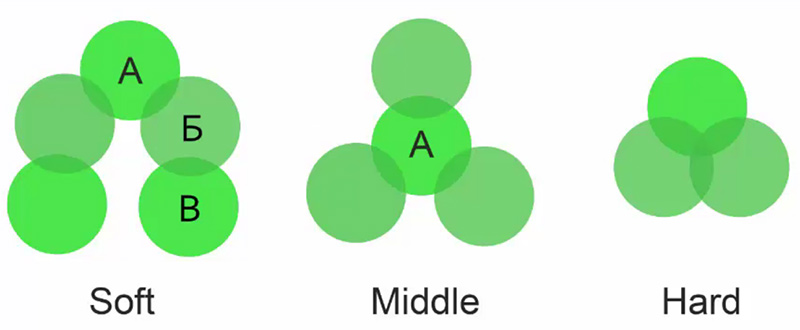
Hard кластеризация даёт высокую точность, этот метод рекомендуется для коммерческих сайтов с высокой степенью конкуренции, soft - высокие показатели полноты и рекомендуется для информационных сайтов, middle – промежуточный метод, своеобразный компромисс между точностью и полнотой.
Миграция запросов - Также называется перегруппировкой «на лету». При включенной функции программа проверит не только минимально допустимое значение совпадающих URL, но и максимальную схожесть запросов. Например, мы установили силу группировки 3 и режим hard или middle. В процессе кластеризации запрос 1 и запрос 2 объединяются в одну группу, т.к. у них 3 общих URL (минимально допустимое значение в данном случае). Без миграции эти запросы так и останутся в одной группе, а с миграцией будет осуществлена проверка на максимальную схожесть, а не только на минимальное совпадение. В данном случае у запроса 2 с запросом 3 общих 7 URL, поэтому с включенной миграцией запрос 2 будет объединён с запросом 3, а не с 1. В большинстве случаев, эта опция сильно повышает качество кластеризации, однако и увеличивает время кластеризации.

Использовать маркерные фразы - При кластеризации с этой опцией, в интерфейсе программы появится столбец с чекбоксами. Если отметить маркерные запросы - это будут главные запросы групп. Этот тип кластеризации нужен, если Вы уже знаете запросы, которые отвечают конкретным страницам Вашего сайта. Если вы делаете новый сайт и не распределяли запросы по страницам с точки зрения логики, то рекомендуется не включать эту опцию.
Расширение семантики - Автоматическое добавление новых фраз в имеющиеся группы справа с учётом интента этих групп. Подробнее тут
Кластеризация по сайту - Кластеризация с учётом имеющихся страниц на определённом сайте, которые уже ранжируются по запросам из семантического ядра. Подробнее на видео:
Кластеризовать по – По умолчанию установлено значение топ10, как и в сборе данных. Например, можно собрать топ20, а потом проверить кластеризацию на топ 5, 10, 15 и 20. Эта опция открывает широчайшее поле для экспериментов в поиске максимально качественной кластеризации именно для вашей ниши. Однако обратите внимание, что топ10 в большинстве случаев является оптимальным значением и не рекомендуется собирать больше топ10 без особой нужды на больших проектах, т.к. это может привести к замедлению работы программы.
Не учитывать - При кластеризации не будут учтены URL, соответствующие данным параметрам. При клике по подсказкам (знак вопроса возле функции), есть пояснения, что именно не будет учитываться. В некоторых случаях включение этих опций может поднять качество группировки. Рекомендуется включать, если точно знаете, что делаете и для чего. По умолчанию эти функции выключены.
В программе KeyAssort сбор данных с поисковых систем необходим для дальнейшей кластеризации. Сейчас данные можно собрать с двух поисковых машин: Google и Яндекс. Также реализован сбор фраз и частот с Яндекс.Wordstat.
Google можно собирать двумя способами: XMLRiver и напрямую. Скорость сбора в xmlriver - от 16 тысяч запросов в час. Напрямую - зависит от количества прокси и скорости решения капчи на сервисе антикапчи; например, для скорости 10 тысяч в час нужно около 50-80 прокси.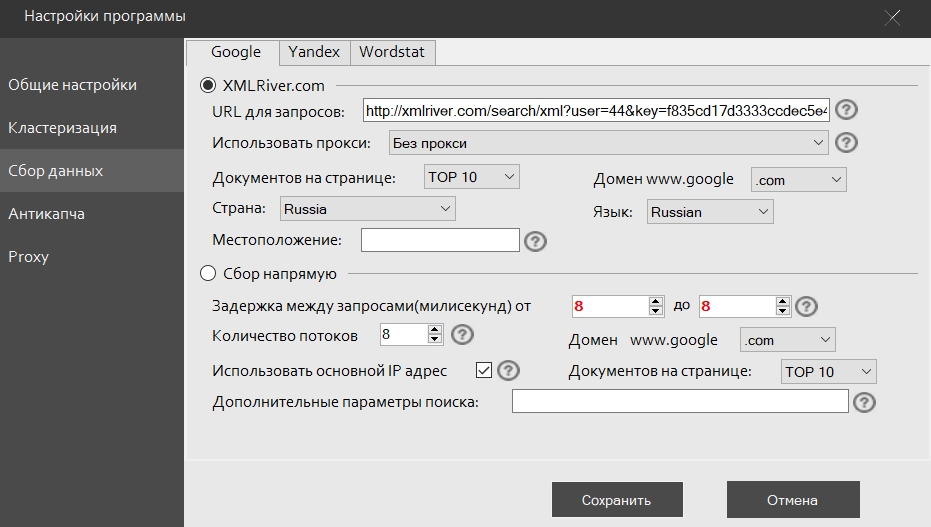
URL для запросов – после регистрации на сервисе XMLRiver в личном кабинете можно скопировать данный URL и сразу начать сбор данных в программе.
Использовать прокси – здесь можно выбрать любой из прокси серверов, которые добавлены во вкладке «Proxy». Рекомендуется использовать только для жителей стран, где сервис по какой-то причине не доступен для сбора. Опция незначительно замедляет сбор.
Домен, страна, язык, местоположение - эти опции должны быть заполнены для более точного соответствия искомой геолокации. Если они заполнены не будут, они будут взяты из кабинета XMLRiver.
Задержка между запросами (милисекунд) – промежуток времени, который программа будет ждать между запросами к поисковику. Функция нужна для уменьшения количества капчи. Рекомендуемое значение – не меньше 1500 милисекунд.
Количество потоков – Число одновременно работающих запросов к поисковой системе. Не может быть больше, чем количество добавленных прокси-серверов плюс основной IP адрес.
Использовать основной IP адрес – При включенной опции данные будут собираться через ваш ip адрес напрямую наряду со всеми добавленными прокси с такой же периодичностью.
Документов на странице – С поисковой выдачи можно собрать не только 10 URL, которые отдаёт Google по умолчанию, но и другое количество (5, 10, 15, 20, 30, 50).
Домен google – Рекомендуется ставить домен той страны, выдачу которой вы хотите получить.
Дополнительные параметры поиска – В поисковой системе Google в GET-запросе можно передать некоторые параметры, которые могут повлиять на выдачу. Например, указать регион поиска по инструкции https://moz.com/ugc/geolocation-the-ultimate-tip-to-emulate-local-search
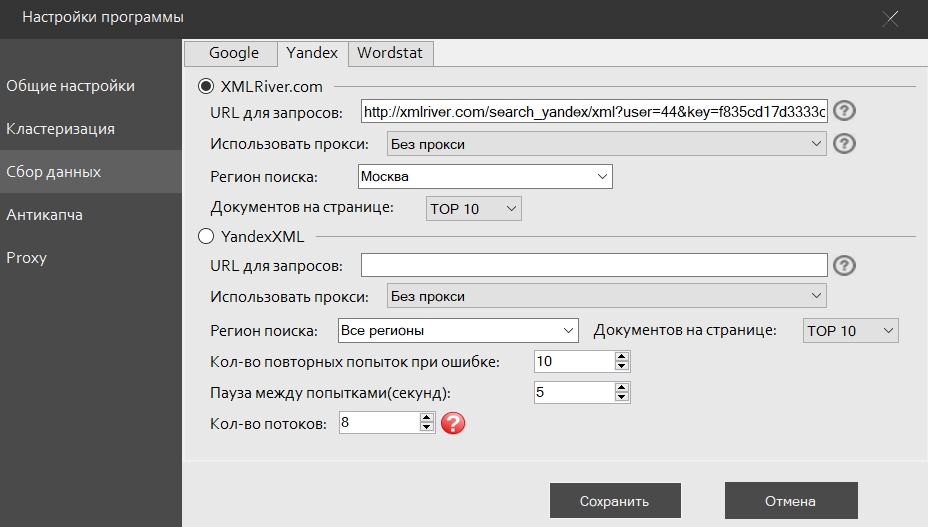
Во вкладке «Yandex» можно настроить сбор данных с поисковой системы Яндекс через XMLRiver или API, получая данные в XML формате. Настройки сервиса XMLRiver для живого поиска Яндекса аналогичны настройкам для Гугла. Сервис Яндекса находится по адресу Yandex Search API (ex Яндекс.XML)
Яндекс через свой API даёт возможность собирать данные с русского сегмента интернета и мирового и турецкого.
Стоимость Yandex Search API напрямую у Яндекса стоит дорого, гораздо дешевле покупать у дилера, например, тот же сервис XMLRiver предоставляет возможность покупать запросы в десятки раз дешевле.
Url для запросов – в это окно нужно вставить строку, полученную в одном из выше описанных сервисов.
Использовать прокси – здесь можно выбрать любой из прокси серверов, которые добавлены во вкладке «Proxy». Рекомендуется использовать только для жителей стран, где заблокирован Яндекс при использовании Yandex Search API для сбора.
Регион поиска – здесь собраны регионы, поддерживаемые яндексом.
Документов на странице - С поисковой выдачи можно собрать не только 10 URL, которые отдаёт Яндекс по умолчанию, но и другое количество (5, 10, 15, 20, 30, 50).
Кол-во повторных попыток при ошибке – при достижении указанного количества сбор данных будет прекращён.
Пауза между попытками – время задержки между запросами после возврата ошибки со стороны Яндекс.
Кол-во потоков – число одновременно работающих потоков.
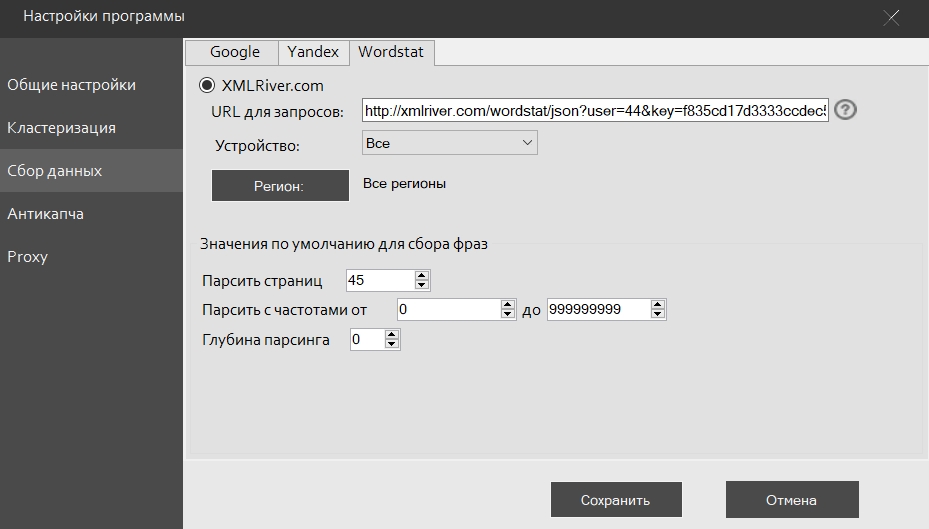
Устройство – Выборка запросов, которые были сделаны с определённого устройства.
Регион – Выборка запросов, которые были сделаны из определённого региона.
Парсить страниц – количество страниц в wordstat, которые будет листать программа по каждому ключевому слову.
Парсить с частотами – при сборе программа будет пропускать фразы, которые не попадают в данный диапазон.
Глубина парсинга – если задать значение больше нуля, программа будет собирать уточнения для уже собранных фраз. Например, при глубине 0 мы соберём 40 страниц по 50 фраз (всего 2000 фраз), а при глубине 1 программа сначала соберёт все уточнения по добавленной фразе (2000 фраз), а потом будет собирать 40 страниц по каждой из собранных 2000 уточнениях.
При включенной функции капчи будут разгадываться автоматически с помощью одного из предложенных сервисов. При выключенной – капчи будут выводиться на экран для самостоятельного разгадывания.
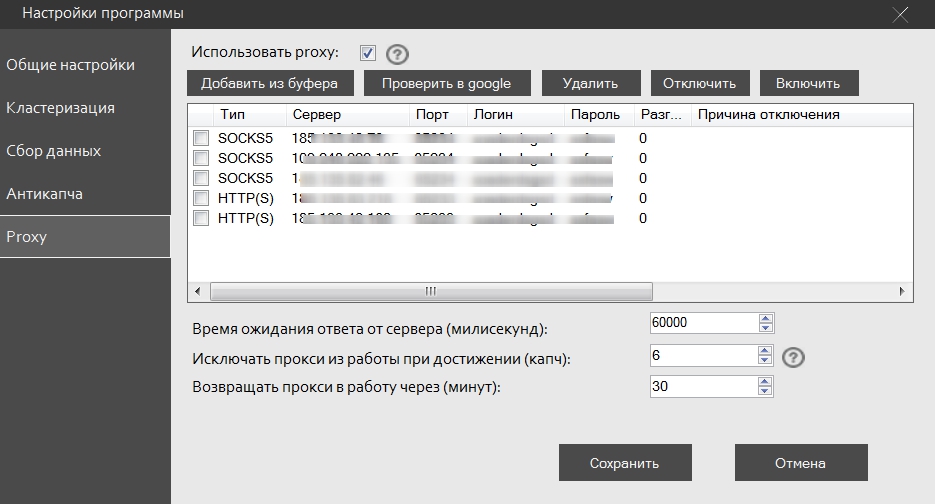
В данном разделе можно добавить прокси-сервера. Клик по кнопке «Добавить из буфера» вызывает всплывающее окно, где прокси могут быть добавлены каждый с новой строки в формате:
Адрес:Порт:Логин:Пароль
или
Адрес:Порт
Если при добавлении сервера вы допустили ошибку, то при двойном клике по любому из параметров добавленного прокси можно произвести редактирование.
Проверить в Google – Функция проверяет доступность поисковой системы Google через отмеченный прокси сервер.
Время ожидания ответа от сервера – время, которое программа будет поддерживать соединение, ожидая ответ от поисковой системы.
Исключать прокси из работы при достижении (капч) – Прокси сервер будет исключён из работы при достижении выставленного количества капч. При значении 0 прокси будет исключён сразу при появлении первой капчи. При значении -1 прокси не будет исключён вообще.
Возвращать прокси в работу через (минут) – При автоматическом исключении прокси из работы, он будет снова включён в сбор данных после выставленного времени.
Программа позволяет через сервис XMLRiver собирать семантическое ядро и частоты к уже собранным с сервиса Яндекса Wordstat или импортированным фразам.
При выборе пункта "Сбор фраз WS", открывается окно, позволяющее выбрать существующую вкладку (или вкладки) с левой стороны программы, куда необходимо собрать фразы. Можно одновременно добавлять маски для сбора фраз для разных вкладок.
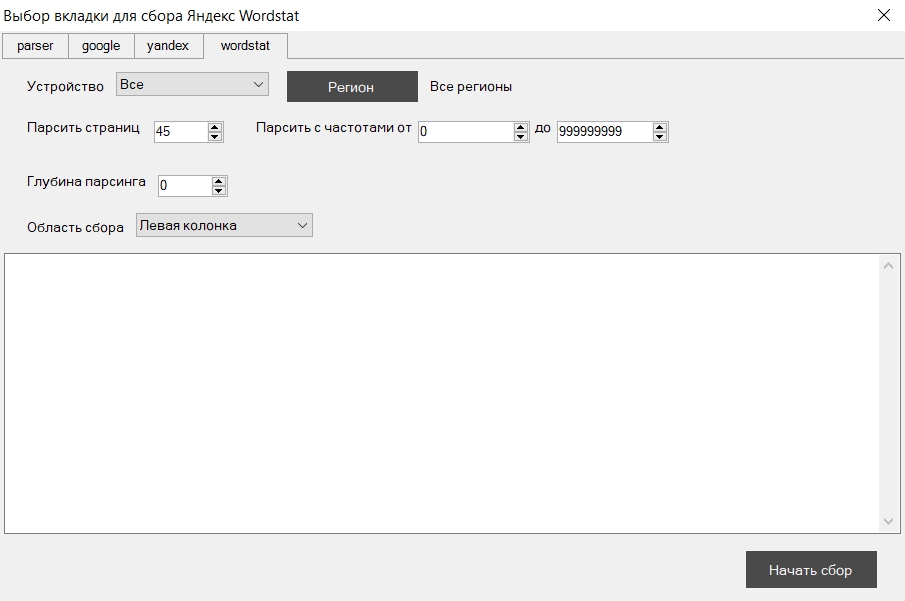
Тут же дублируются опции, которые указаны в настройках программы по умолчанию. И указана ещё одна опция "Область сбора", позволяющая собирать данные как с левой, так и с правой колонки Wordstat.
После нажатия кнопки "Начать сбор", прогресс сбора отображается справа внизу программы.

При выборе пункта "Частоты WS", программа предложит выбрать какую из частот нужно собрать и соответствие базовой, фразовой, точной и уточнённых частот столбцам в программе, если они уже имеются. Если не имеются, они будут созданы. Процесс сбора отображается в прогресс-баре и соответствующем столбце.
Сбор данных начинается с выбора источника получения данных. В основном интерфейсе программы (слева внизу) выбирается поисковая система:
И после настройки необходимых параметров, можно приступить к сбору данных. В интерфейсе программы это осуществляется кнопкой «Поисковая выдача». При клике на эту кнопку появляется выпадающее меню, в котором следует выбрать нужный источник данных.
После выбора источника, следует выбрать, с какой стороны нужно осуществлять сбор. Если сбор уже начинался и не был закончен, программа предложит собрать данные заново, либо дособрать.
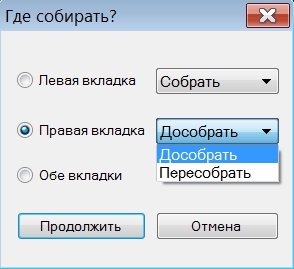
После этого обратите внимание на строку состояния внизу программы - прогресс-бар (1) должен показывать, что процесс движется. А если же вы не видите движения, наведите курсор мыши на текст «Попытка №..» (2) и во всплывающем окне будет показана причина остановки сбора данных.

Сбор данных можно в любой момент прервать кнопкой «Отмена», которая появляется в процессе сбора. Собранные данные при этом не исчезнут, т.к. в программе реализовано автосохранение.

Очистить загруженные URL – Результаты сбора данных можно в любой момент очистить.

Обратите внимание! Вы можете для одного проекта собрать данные как по одной, так и по двум поисковым системам, переключая их в интерфейсе программы.
После того, как фразы импортированы, данные собраны и произведены настройки кластеризации, можно переходить к самому процессу группировки. Предварительно в интерфейсе программы, не переходя в настройки, можно скорректировать силу группировки (1) и вид кластеризации(2):
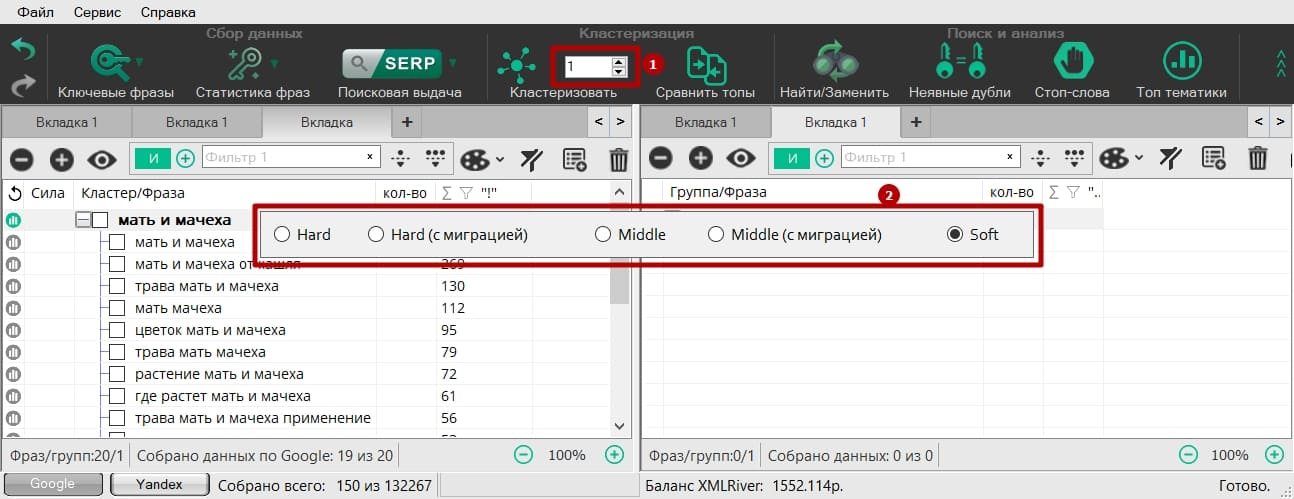
Быстрая замена вида кластеризации осуществляется с помощью горячих клавиш ctrl+Tab или ctrl+shift+Tab. Для начала процесса группировки достаточно нажать на кнопку «Кластеризовать»
После окончания процесса, о чём программа уведомит, в левой части программы вместо списка фраз появятся папки с ключевыми словами внутри. Группированные фразы будут в папках с названием одной из фраз, находящейся в группе. А также одна папка с названием «НЕ СГРУППИРОВАНО», в которой содержатся фразы, не нашедшие связей с другими фразами при текущих настройках кластеризации.
Развернуть одну папку можно с помощью знака плюс с левой стороны от группы. Развернуть и свернуть все группы можно с помощью глобальных кнопок:
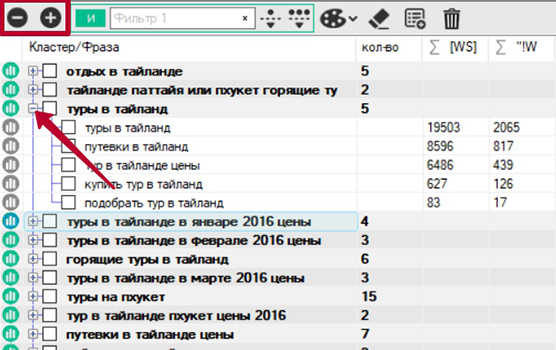
После первичной кластеризации и просмотра всех групп, может возникнуть потребность перекластеризовать некоторые группы, т.к. фразы внутри логически разнородные. Для этого достаточно отметить чекбокс напротив интересующей группы (или групп) и нажать всё ту же кнопку «Кластеризовать». При этом перегруппируются не все фразы, а только отмеченные.
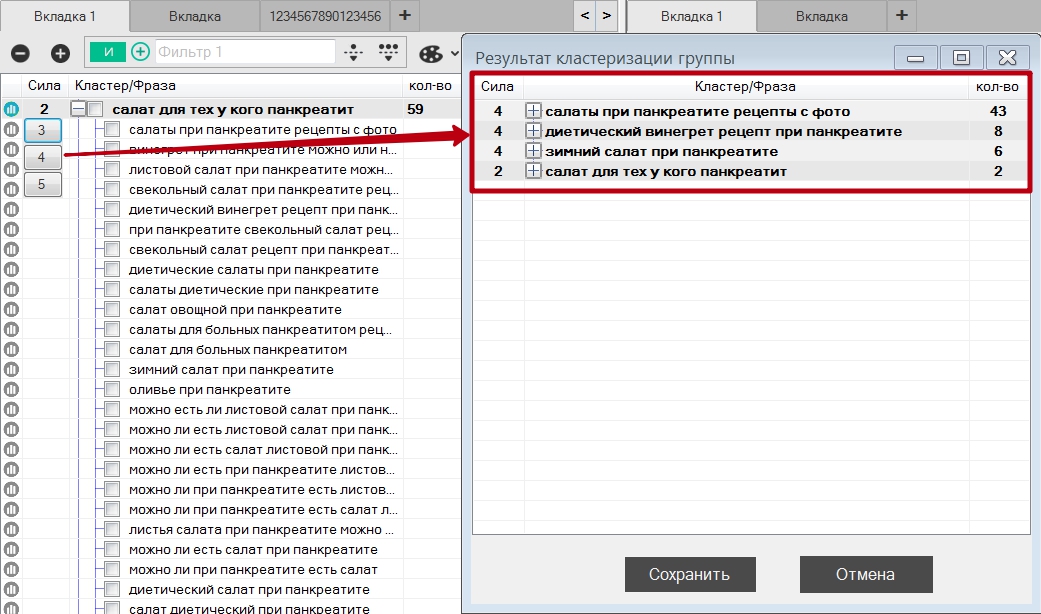
Также после кластеризации возле каждой из полученных групп отображается сила кластеризации, которая была применена. При нажатии на эту цифру, отобразится возможность предпросмотра кластеризации при условии повышения силы. При нажатии "Сохранить" перекластеризованные с бОльшей силой группы будут помещены в конец списка, при нажатии "Отмена" ничего меняться в изначальной кластеризации не будет.
Если вы знаете запросы, которые соответствуют определённым страницам вашего сайта, то можно использовать кластеризацию с маркерными фразами. При выборе этой опции в настройках, в левой части интерфейса программы, напротив фраз, появится дополнительный столбец с чекбоками. При отметке одной или нескольких фраз в этом столбце и нажатии кнопки «Кластеризовать», отмеченные фразы станут вершинами кластера (каждая из отмеченных фраз сформирует свою группу). Если нужно отметить большое количество фраз, можно выделить интересующие фразы, кликнуть по ним правой кнопки мыши и в появившемся контекстном меню выбрать «Отметить выделенные фразы как маркерные»
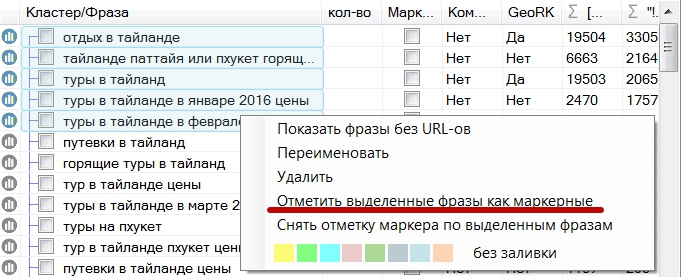
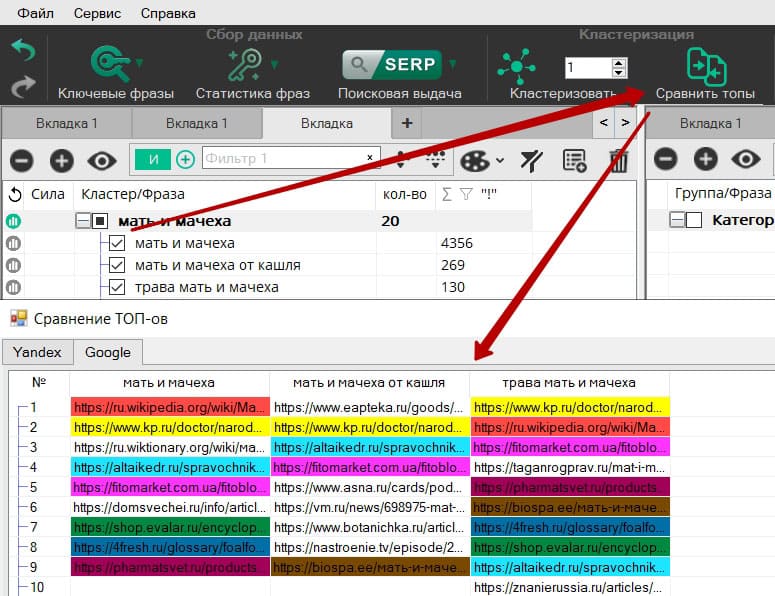
В программе есть возможность наглядно проверить совпадение URL у различных фраз. Для этого достаточно отметить от 2 до 10 фраз и нажать "Сравнить топы". Во всплывающем окне будут показаны топы по каждой фразе с цветовой отметкой совпадений. Посмотреть совпадения можно по Google и по Яндексу при условии, что предварительно были собраны данные.
Инструменты из этого раздела созданы для чистки семантического ядра. Позволяют максимально полно очистить собранные ключевые слова от нежелательных по целому ряду параметров.

При клике по данной кнопке на основной панели инструментов, появляется такое всплывающее окно:
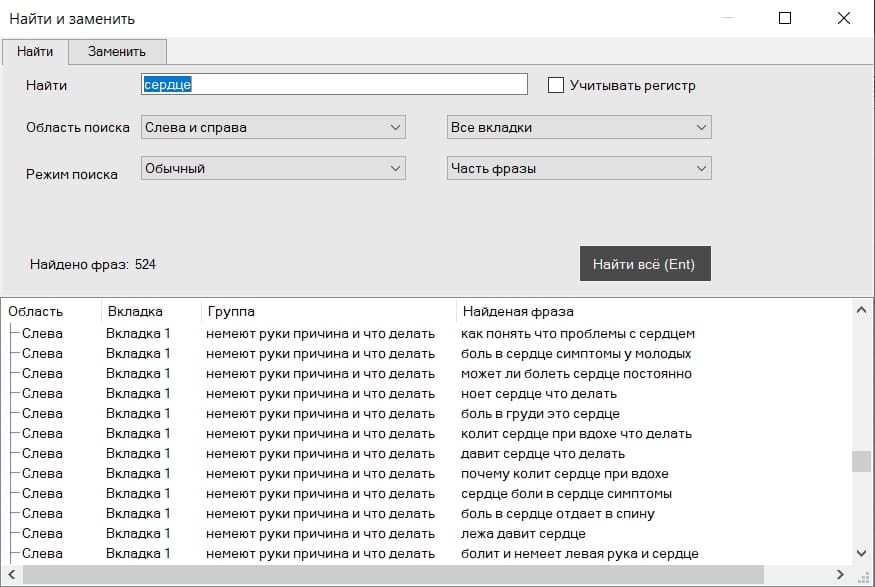
Поиск можно производить с такими опциями:
После нажатия на кнопку "Найти всё", внизу этого всплывающего окна программа покажет все найденные результаты. При клике левой кнопкой мыши по ним, фразы будут подсвечены в основном интерфейсе программы.
Во вкладке "Заменить" есть те же самые опции поиска фраз, только добавлено окно для фразы или её части, на которую нужно заменить искомую фразу. После нажатия на кнопку "Найти всё" также отобразятся все найденные результаты и дальше с помощью кнопок "Заменить (F1)" или "Заменить всё" можно менять фразы или части фраз.
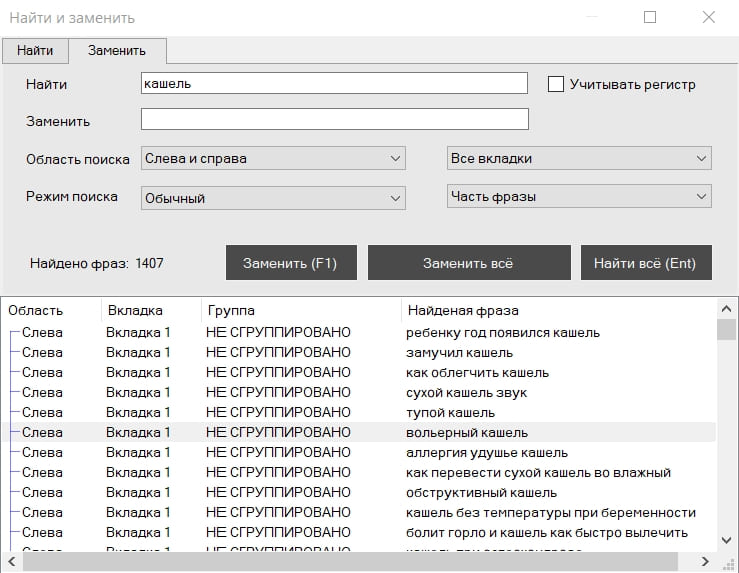
Инструмент может быть полезен для замены устаревших фраз, например, когда нужно заменить прошлый год на текущий.
Кликая по соответствующей кнопке, мы видим всплывающее окно, которое покажет опции поиска неявных дублей.
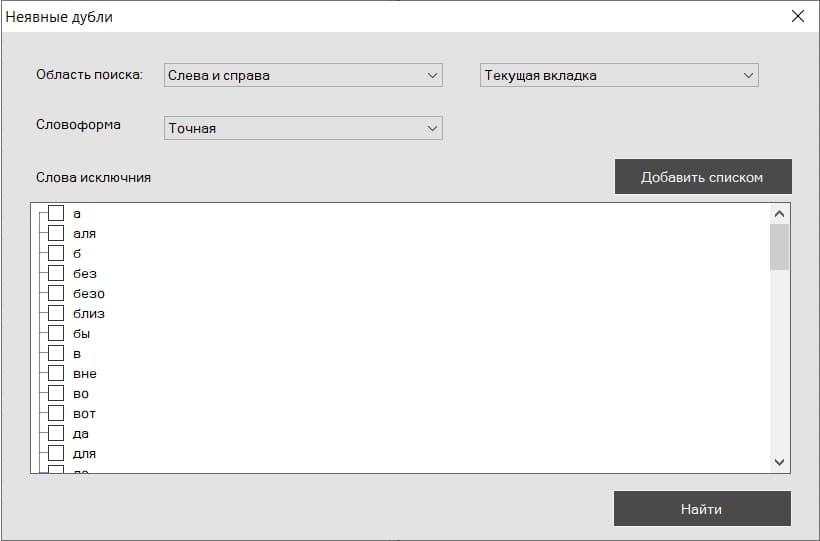
После установки всех настроек и нажатия кнопки "Найти" в левой части программы появится специальная вкладка "Неявные дубли" (1). В этой вкладке будут отображены все дублирующиеся фразы. Колонка "Расположение" (2) покажет путь до фразы, если по расположению кликнуть, программа переместит фокус во вкладку и группу, где находится эта фраза. Также в этой специальной вкладке есть кнопка "Умная отметка" (3), которая отметит все фразы в группе, кроме верхней. Предварительно фразы можно отсортировать по любому из столбцов, например, по частоте.
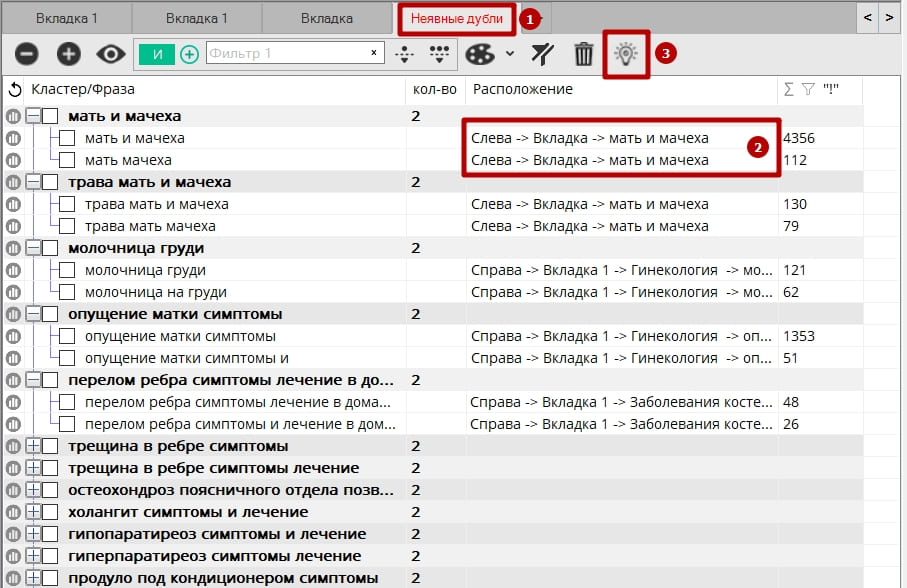
Фразы, удалённые в этой спец-вкладке, будут удалены из своих вкладок. Также отметка цветом перенесёт цвет в свои вкладки. Фразы из этой вкладки можно переносить в другие вкладки, при этом они будут вырезаны из своей текущей вкладки.
Эту специальную вкладку можно закрыть, кликнув правой кнопкой мыши по ней.
При выборе этой функции появляется всплывающее окно, которое предлагает опции для поиска стоп-слов.
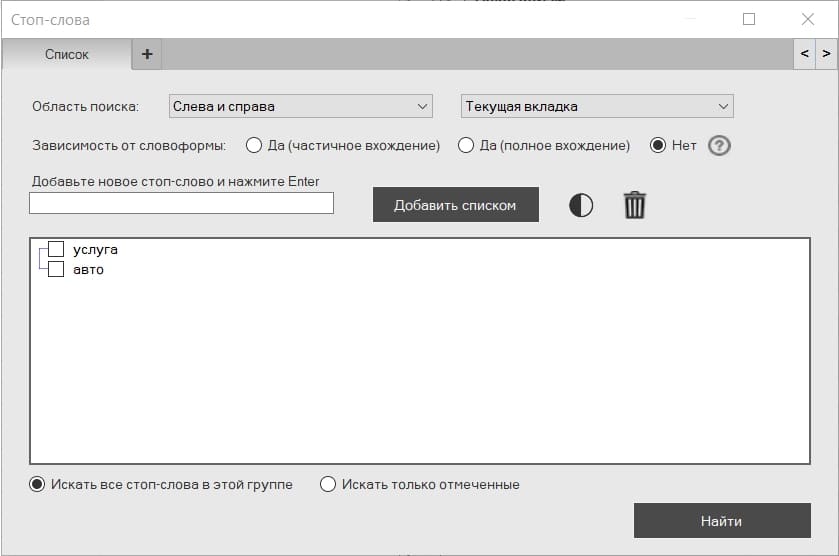
В этом окне доступна возможно создавать различные списки стоп-слов. Достаточно нажать на плюс для добавления следующего списка.
Дальше следуют такие опции:
Да (частичное вхождение) - например, вы ищете слово "тип". При выборе этой опции программа найдёт все слова, где встречается часть этого слова - типичный, логотип ...
Да (Полное вхождение) - при поиске слова "тип", программа найдёт фразы, содержащие слово "тип" и больше ничего.
Нет - При поиске "тип", программа найдёт все склонения и спряжения этого слова - типы, типов, типа...
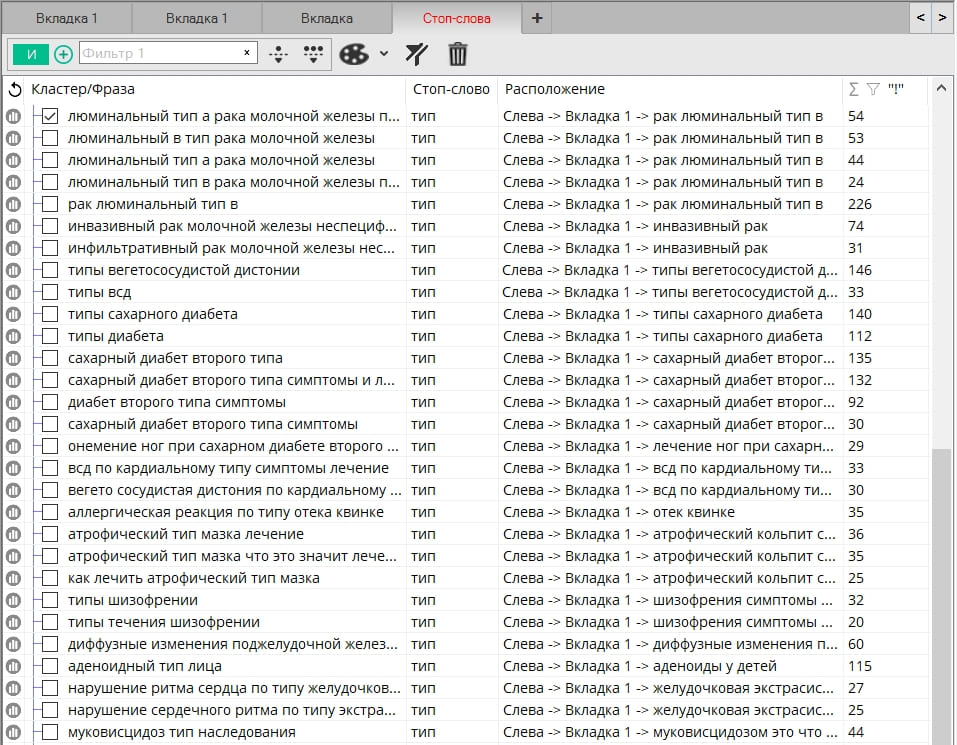
При нажатии кнопки "Найти", в левой части программы появится вкладка "Слоп-слова". Если фразы удалить здесь, они будут удалены из своих вкладок. Двойной клик по ячейке в столце "Расположение" перенесёт фокус на владку и группу, где находится фраза.
При клике по кнопке «Топ тематики» в главном меню программы будет отображено всплывающее окно, содержащее сайты, которые были встречены в выдаче при сборе данных, в порядке по встречаемости (популярности) в данном семантическом ядре.
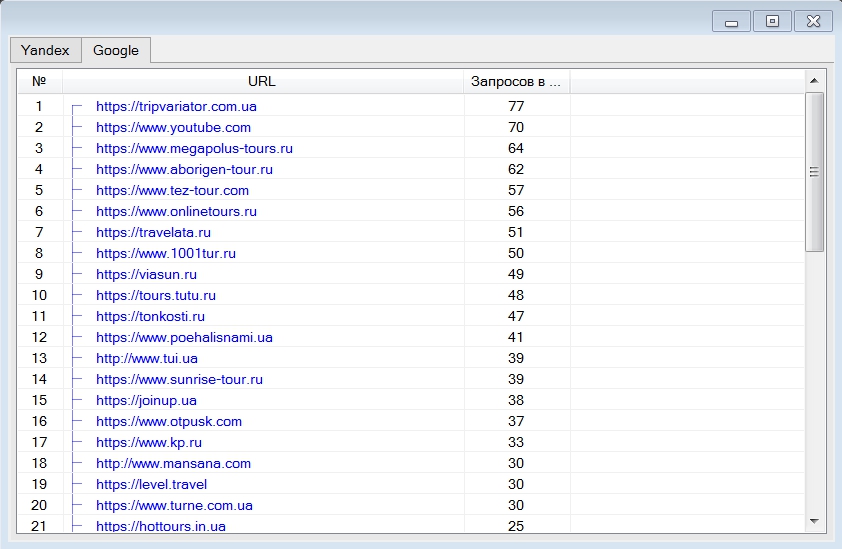
Функция нужна для того, чтобы можно было посмотреть на самых сильных конкурентов в данной нише. Обратите внимание, здесь показываются только сайты, которые были встречены 10 и более раз.
В основном интерфейсе программы существует возможность посмотреть топ URL для каждой фразы (2) и для группы фраз (1).
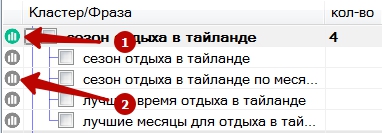
В окне, показывающем топ URL по группе фраз, можно посмотреть по каким фразам ранжируется данный URL и на каком месте в выдаче он встречается (в скобках возле фразы).
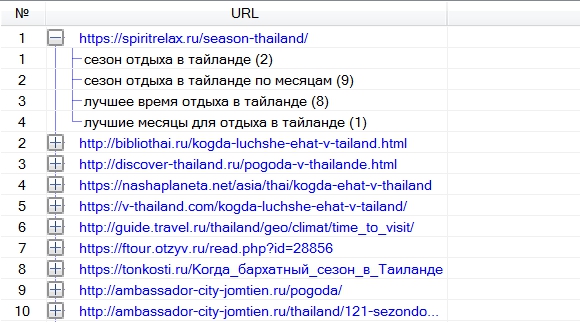
В программе KeyAssort реализовано удобное построение структуры сайта, которое может использоваться как доработка автоматической кластеризации, так и как полностью ручная группировка семантического ядра.
Для структурирования в программе есть 2 окна: левое и правое. В левое окно изначально загружаются фразы и могут быть автоматически кластеризованы. Правое окно служит для окончательного построения структуры сайта.
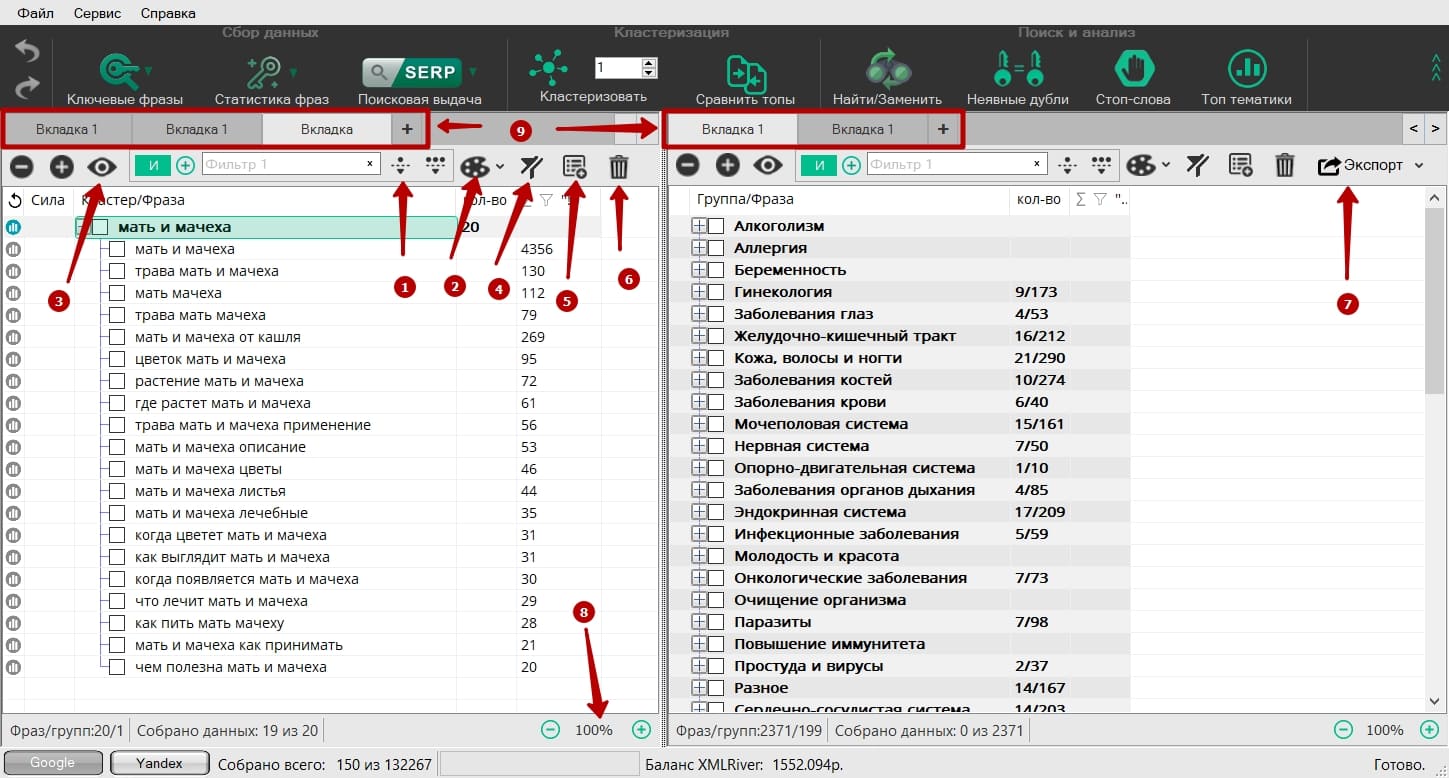
Меню каждой из сторон программы содержит такие элементы:
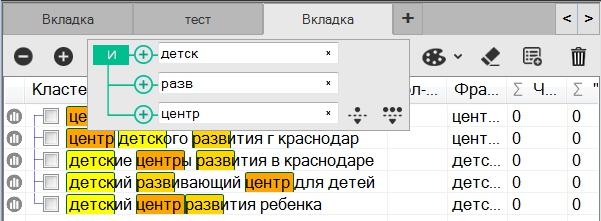
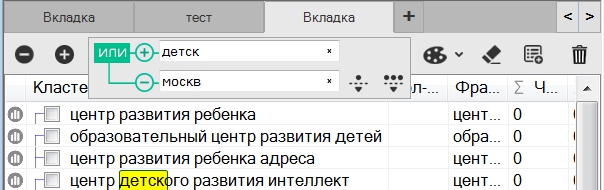
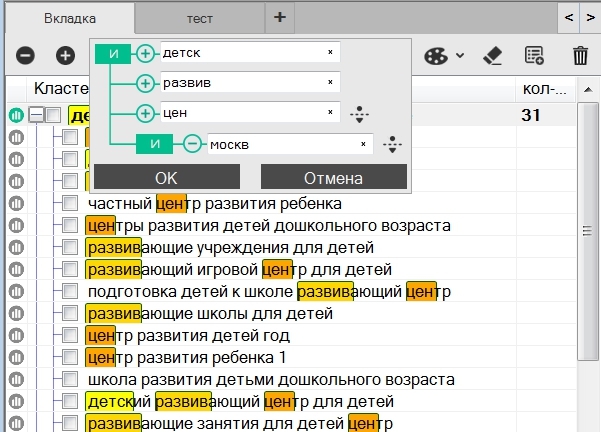
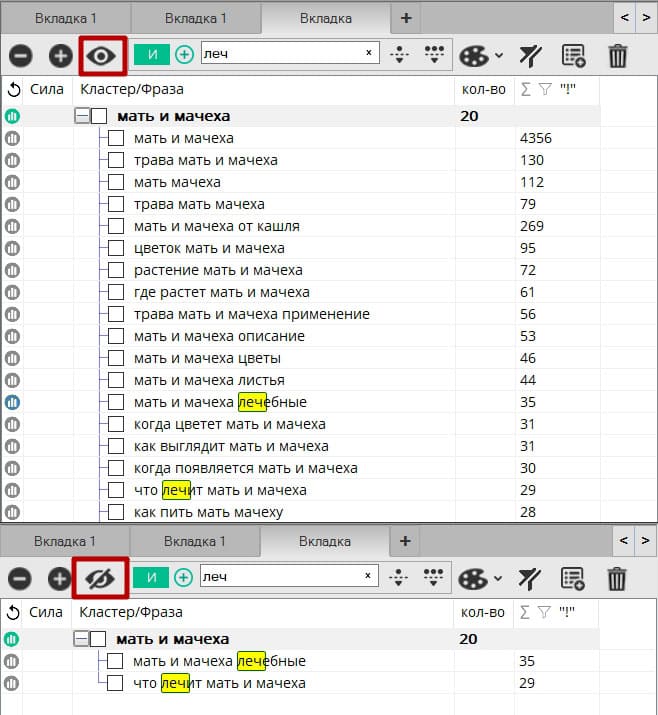
В первую очередь стоит обратить внимание на различие между отмеченной фразой и выделенной:
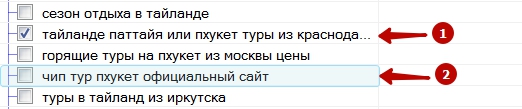
1 – отмеченная;
2 – выделенная.
Для выделения нескольких фраз и/или групп можно зажать клавиши ctrl или Shift. Для быстрой отметки нескольких фраз и/или групп достаточно их выделить и нажать на Пробел.
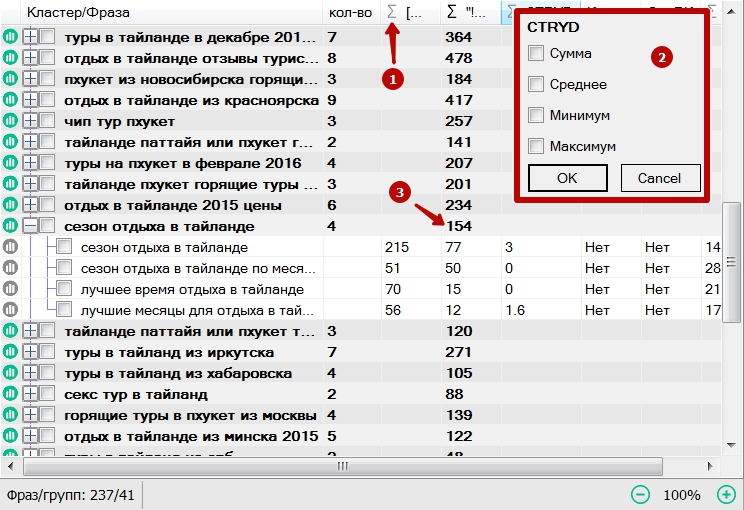
При импорте в программу фраз с параметрами в названии столбца, содержащего числовые данные, отображается значок суммы (1), при нажатии на который, появляется окно (2) с выбором суммы, среднего, минимального и максимального значений. Вычисленное значение параметров будет показано напротив названия группы выше параметров фраз (3).
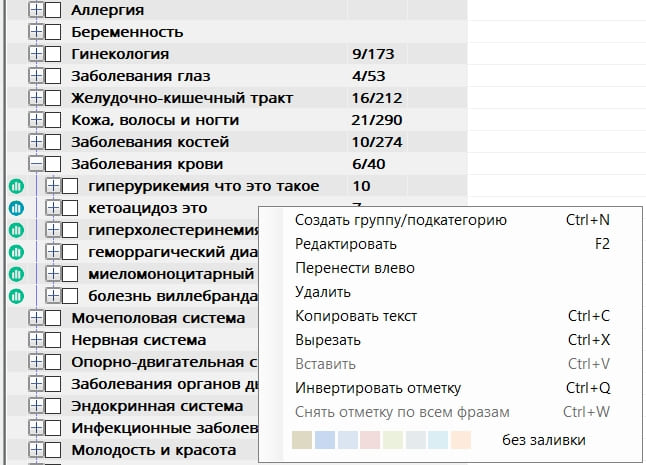
В левой части программы группы могут содержать только фразы, вложенность групп не предусмотрена, в правой же части есть возможность создавать неограниченную вложенность групп. Внимание! Не рекомендуется создавать более 8 уровня вложенности, т.к. при дальнейшем экспорте в xlsx файл, эксель поддерживает максимум 8 уровней.
Для создания вложенной группы требуется кликнуть правой кнопкой мыши по группе, для которой планируется создать вложенность, и в контекстном меню выбрать «Создать группу/подкатегорию». Обратите внимание, группа и категория – это одна сущность, которая может содержать как вложенные группы, так и фразы.
В правой части программы группы можно вручную расставлять относительно друг друга. Если пользуетесь этой функцией, в "Общих настройках -> Настройках сортировки" выберете "Только фразы", чтобы ручная расстановка групп не сбилась при автоматической сортировке.
Фразы и группы можно перетаскивать как внутри левой и правой областей программы, так и между ними. Возможности по перетаскиванию фраз и групп внутри программы:
В общем, любую выделенную фразу или несколько, группу или несколько можно перетянуть на другую группу. Таким образом, в правой части программы моделируется структура сайта с категориями и подкатегориями, содержащие группы фраз, на основании которых в дальнейшем должна будет спроектирована страница сайта.
Внимание! Вместо перетягивания фраз и групп мышкой, их можно вырезать через клик правой кнопкой мыши и выбор соответствующего пункта контекстного меню и вставлять в нужную локацию.
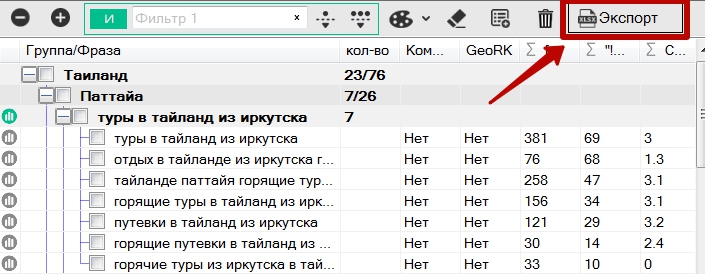
Программа поддерживает экспорт созданной структуры в правой части. Экспорт осуществляется в двух форматах:
- Эксель *.xlsx
- Key Collector
- Поисковая выдача *.csv
Формат *.xlsx содержит три вкладки:
Экспортный файл Key Collector содержится в Формате *.xml и может быть импортирован в Key Collector, начиная с 4-й версии программы
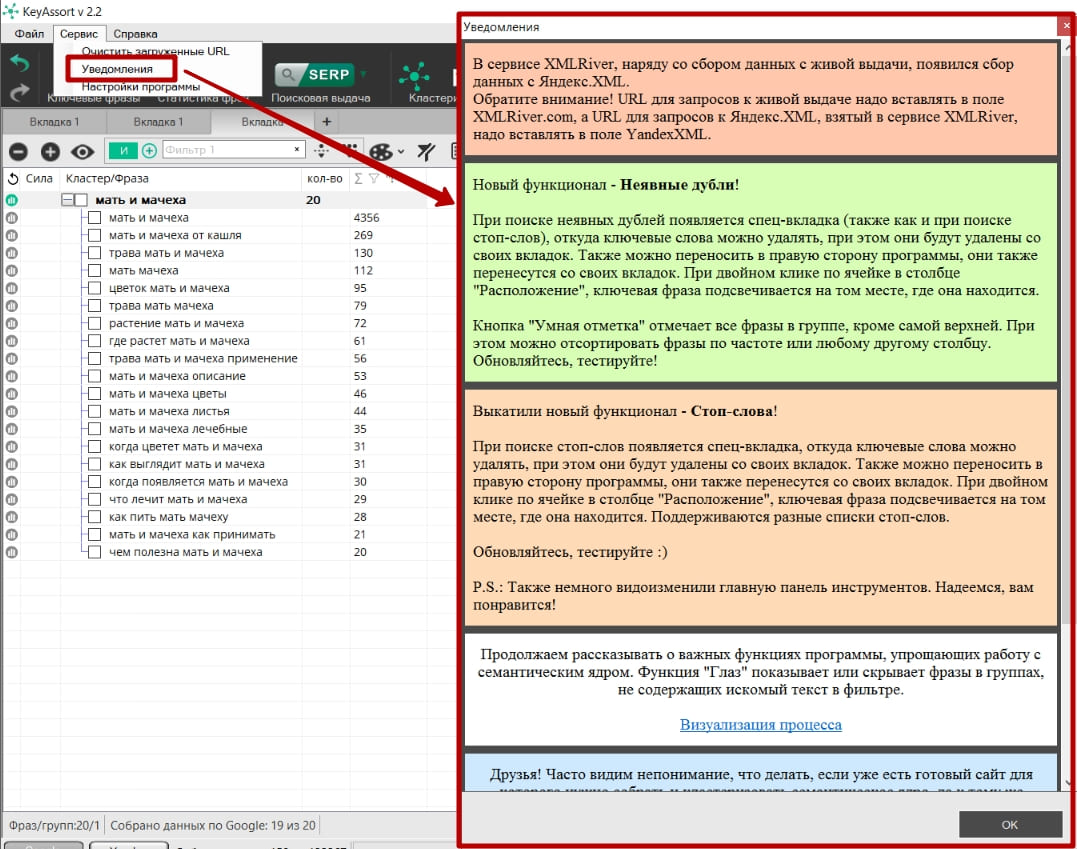
Уведомления – Архив о важных новостях в работе программы можно посмотреть тут.
2024 © KeyAssort. Все права защищены.
Партнёрская программа | Политика конфиденциальности | Лицензионное соглашение